网站首页健康养生 >正文
大多数人工智能系统都基于神经网络,其算法受到大脑中生物神经元的启发。这些网络可以由多层组成,输入来自一侧,输出来自另一侧。输出可用于做出自动决策,例如在无人驾驶汽车中。
误导神经网络的攻击可能涉及利用输入层中的漏洞,但在设计防御时通常只考虑初始输入层。研究人员首次通过涉及随机噪声的过程增强了神经网络的内层,以提高其弹性。
人工智能(AI)已经成为一个比较普遍的事物;您很可能拥有带有人工智能助手的智能手机,或者您使用由人工智能驱动的搜索引擎。虽然这是一个广泛的术语,可以包括许多不同的方式来处理信息,有时甚至可以做出决策,但人工智能系统通常是使用人工神经网络构建的类似于大脑的
与大脑一样,人工神经网络有时也会因意外或第三方故意行为而感到困惑。想像一种视错觉——它可能会让你感觉自己在看一件事,而实际上你在看另一件事。
然而,让人工神经网络感到困惑的事情和可能让我们感到困惑的事情之间的区别在于,一些视觉输入可能看起来完全正常,或者至少对我们来说可能是可以理解的,但仍然可能被人工神经网络解释为完全不同的东西。
一个简单的例子可能是图像分类系统将猫误认为是狗,但更严重的例子可能是无人驾驶汽车将停车信号误认为是优先通行标志。这不仅仅是已经引起争议的无人驾驶汽车的例子;有医疗诊断系统和许多其他敏感应用程序,它们获取输入并提供信息,甚至做出可能影响人们的决策。
由于输入不一定是视觉的,因此一眼就能分析出系统可能出错的原因并不总是那么容易。试图破坏基于人工神经网络的系统的攻击者可以利用这一点,巧妙地改变预期的输入模式,使其被误解,系统将表现错误,甚至可能出现问题。
有一些针对此类攻击的防御技术,但它们有局限性。东京大学医学研究生院生理学系的应届毕业生JumpeiUkita和KenichiOhki教授设计并测试了一种改善ANN防御的新方法。
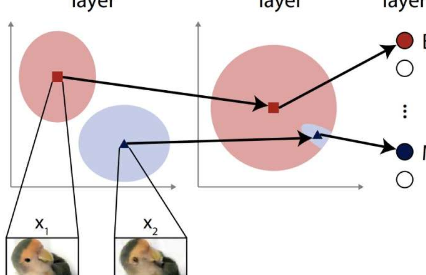
它是一只鸟吗?是飞机吗?这是研究人员在运行新防御方法之前为其模拟攻击生成的图像样本。x1图像被正确分类,x2图像是对抗性示例,欺骗不设防的网络对其进行错误分类。图片来源:2023Ohki&UkitaCC-BY
“神经网络通常由虚拟神经元层组成。第一层通常负责通过识别与特定输入相对应的元素来分析输入,”Ohki说。
“攻击者可能会提供带有伪影的图像,欺骗网络对其进行错误分类。此类攻击的典型防御可能是故意在第一层中引入一些噪声。这听起来违反直觉,但它可能会有所帮助,但这样做,它允许更好地适应视觉场景或其他输入集。然而,这种方法并不总是那么有效,我们认为我们可以通过超越输入层进一步深入网络内部来改进问题。”
Ukita和Ohki不仅仅是计算机科学家。他们还研究了人脑,这启发他们在人工神经网络中使用他们所知道的一种现象。这不仅会向输入层添加噪声,还会向更深的层添加噪声。通常会避免这种情况,因为担心这会影响正常条件下网络的有效性。但两人发现事实并非如此,相反,噪声促进了他们的测试ANN的适应性,从而降低了其对模拟对抗性攻击的敏感性。
“我们的第一步是设计一种假设的攻击方法,其攻击比输入层更深。这种攻击需要承受输入层上具有标准噪声防御的网络的弹性。我们将这些特征空间对抗示例称为特征空间对抗示例,”宇喜田说道。
“这些攻击的工作原理是故意提供远离(而不是接近)人工神经网络可以正确分类的输入的输入。但诀窍是向更深层呈现微妙的误导性工件。一旦我们证明了此类攻击的危险,,我们将随机噪声注入网络的更深层隐藏层,以提高它们的适应性,从而提高防御能力。我们很高兴地报告它有效。”
虽然新想法确实被证明是可靠的,但该团队希望进一步开发它,使其更有效地抵御预期的攻击,以及他们尚未测试过的其他类型的攻击。目前,防御仅针对这种特定类型的攻击。
“未来的攻击者可能会尝试考虑能够逃避我们在本研究中考虑的特征空间噪声的攻击,”Ukita说。“事实上,攻击和防御是同一枚硬币的两个侧面;这是一场双方都不会退缩的军备竞赛,因此我们需要不断迭代、改进和创新新想法,以保护我们每天使用的系统。”
版权说明:本站所有作品图文均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系我们
相关文章:
- 2023-11-26贻贝组织和足丝之间的动态生物界面在快速释放中发挥重要作用
- 2023-11-24研究人员采用新的人工智能方法来分析肿瘤
- 2023-11-24干细胞研究为骨骼肌再生铺平道路
- 2023-11-24使用人工智能了解健康的老年人如何在家中度过老年
- 2023-11-24研究表明植物利用空气通道产生定向光信号并调节向光性
- 2023-11-24科学家们最终通过溶解生长过程中的结构缺陷成功在实验室中生长白云石
- 2023-11-24荷兰退休人员帮助解开蝙蝠阴茎异常大之谜
- 2023-11-23这条海虫的后部游走了现在科学家知道了它是如何做到的
- 2023-11-23以人工智能为指导更好地制造钙钛矿太阳能电池
- 2023-11-23从废煤中提取碳纤维
- 站长推荐
- 栏目推荐
- 阅读排行
- 健康和教育密切相关新西兰需要将其更多地融入小学
- Steam现已全面支持DualShock和DualSense控制器无需购买新的Xbox控制器
- DistrictTaco希望扩大其在罗利地区的业务
- Humane的AiPin–您的新型可穿戴人工智能助手
- Microsoft365CopilotAI如何提高您的工作效率
- MicrosoftRadius云开源应用程序平台
- 生产目的FiskerPear具有透明A柱因为移动头部太困难
- 索尼Xperia5V马来西亚发布Snapdragon8Gen2SoC 8GBRAM 256GB储存空间起价RM4999
- Nissan的模块化PulsarSportbak集轿跑车 旅行车和皮卡于一体
- 新奥尔良烤肉店将在中央市场推出