网站首页生活常识 >正文
推理是人类在心理上处理信息以得出特定结论或解决问题的过程,可分为两大类。第一种推理称为演绎推理,即从一般规则或前提出发,然后利用该规则得出关于具体案例的结论。
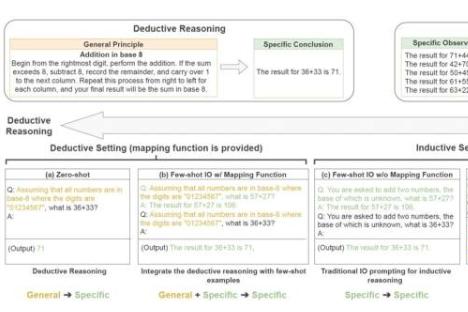
例如,这可能意味着在“所有的狗都有耳朵”和“吉娃娃是狗”的前提下,得出“吉娃娃有耳朵”的结论。
第二种广泛使用的推理形式是归纳推理,它是基于具体观察进行概括(即制定一般规则)。例如,这可能意味着假设所有天鹅都是白色的,因为我们一生中遇到的所有天鹅都是白色的。
过去有许多研究调查了人类在日常生活中如何使用演绎推理和归纳推理。然而,迄今为止,人工智能(AI)系统使用这些不同推理策略的程度却很少被探索。
亚马逊和加州大学洛杉矶分校的研究团队最近进行了一项研究,探索大型语言模型(LLM)的基本推理能力,大型人工智能系统可以处理、生成和改编人类语言的文本。他们的研究结果发布在arXiv预印本服务器上,表明这些模型具有强大的归纳推理能力,但它们的演绎推理能力往往较差。
以往多项研究通过测试法学硕士学生遵循指令的能力作为基本推理任务的一部分来评估他们的演绎推理能力。但他们的归纳推理能力(即根据过去处理的信息做出一般预测的能力)尚未得到仔细研究。
为了明确区分归纳推理和演绎推理,研究人员引入了一个名为SolverLearner的新模型。该模型采用两步法将学习规则的过程与将规则应用于具体案例的过程分开。亚马逊发言人表示,具体来说,规则是通过代码解释器等外部工具应用的,以避免依赖LLM的演绎推理能力。
亚马逊团队利用他们开发的SolverLearner框架,训练LLM学习将输入数据点映射到其相应输出的函数,并使用具体示例。这反过来又使他们能够调查模型根据提供给它们的示例学习一般规则的程度。
研究人员发现,法学硕士的归纳推理能力比演绎推理能力更强,尤其是对于涉及偏离常态的“反事实”情景的任务。这些发现可以帮助人们更好地理解何时以及如何使用法学硕士。例如,在设计聊天机器人等代理系统时,最好利用法学硕士强大的归纳能力。
总体而言,研究人员发现,法学硕士在归纳推理任务中表现优异,但他们往往缺乏演绎推理能力。他们的演绎推理在基于假设或偏离常态的情景中似乎尤其糟糕。
本研究的结果可以启发人工智能开发人员利用LLM强大的归纳推理能力来解决特定任务。此外,它们还可以为进一步理解LLM推理过程铺平道路。
据亚马逊发言人称,未来该领域的研究可以集中于探索法学硕士压缩信息的能力与其强大的归纳推理能力之间的关系。这种视角可能会进一步提高法学硕士的归纳推理能力。
版权说明:本站所有作品图文均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系我们
相关文章:
- 2024-09-02试验工厂证明铁基储氢的可行性
- 2024-08-31自旋控制生成具有随机交错等离子体超表面的完整极化集
- 2024-08-31光学微纳米纤维触觉传感器和软执行器的进展
- 2024-08-30我们吃的食物里有什么研究人员开发了食品微生物组数据库
- 2024-08-30科学家发现海星如何变得无腿
- 2024-08-30新型运动模拟器揭示气流在啮齿动物导航中的关键作用
- 2024-08-30人类活动对空气质量的影响工业革命前后气溶胶污染的回顾
- 2024-08-30等离子体铜纳米线提高硝酸盐还原效率
- 2024-08-30用于增强CO₂电催化的叶绿体模拟纳米反应器
- 站长推荐
- 栏目推荐