网站首页生活常识 >正文
美国能源部橡树岭国家实验室的计算科学家团队生成并发布了规模空前的数据集,提供了超过1000万个有机分子的紫外可见光谱特性。了解分子如何与光相互作用对于揭示其电子和光学特性至关重要,这反过来又在太阳能电池或医学成像系统等产品中具有潜在的光活性应用。
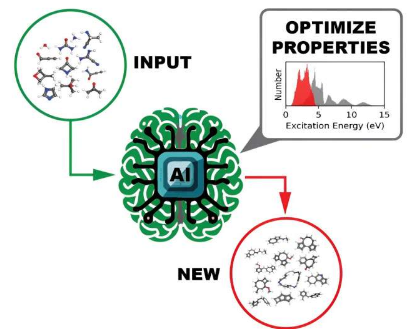
ORNL团队利用橡树岭领先计算设施的高性能计算资源进行量子化学计算,生成大量数据集。对于每一个有机分子,团队使用各种近似值进行原子材料建模计算,以计算感兴趣的不同激发态特性。该团队的研究结果发表在《科学数据》上。
开源数据集的最终用途是训练深度学习模型来识别具有定制光电和光反应特性的分子,一种比当前方法更快、更容易执行的方法。
“使用深度学习模型进行分子设计至关重要,因为搜索这些分子必须探索的化学空间非常大,”主要作者、橡树岭国家实验室计算科学与工程部门的数据科学家MassimilianoLupoPasini说道。
“实验和现有的第一原理计算都是基于决定物质和能量在亚原子水平如何相互作用的物理定律,但由于不同的原因,它们根本无法承受。实验是劳动密集型的,第一原理计算很容易冲击超级计算设施。但深度学习模型提供了非常有前途的工具来克服这些障碍,”卢波·帕西尼说道。
当ORNL计算化学和纳米材料科学小组组长StephanIrle发现分子的紫外-可见光谱是用深度学习模型进行预测的有用属性时,该项目就开始了。
构建足够复杂的深度学习模型来识别所需的分子特性,需要使用大量数据对其进行训练,以探索化学空间的所有不同区域。收集的数据越多,在其上训练的深度学习模型就越能实现有效运行所需的鲁棒性和泛化性。然而,为可扩展的深度学习收集如此大量的科学数据可能会带来数据流问题,尤其是在拥有多个用户的设施中,例如OLCF(位于ORNL的DOE科学办公室用户设施)。
“生成大量数据时出现的一个挑战是需要管理的文件数量急剧增加。如果管理不当,如此大的数据量可能会损害并行文件系统的功能,而并行文件系统是最先进的HPC设施的重要组成部分。”卢波·帕西尼说道。
为了应对这一挑战,LupoPasini与ORNL计算机科学家KshitijMehta合作开发了一款可扩展的工作流程软件,确保量子力学代码生成的文件得到正确处理,而不会对文件系统造成压力,例如OLCF的Orion,它是处理超级计算机系统上数据的输入、输出和存储的共享资源。
作为概念验证测试,该团队生成了包含96,766个分子的GDB-9-Ex数据集,这些分子由碳、氮、氧和氟组成,最多有9个非氢原子。结果表明,设计的工作流程是有效的,并且深度学习训练准确地预测了紫外-可见光谱中最相关峰的位置和强度。
继最初的成功之后,该团队进一步扩大了ORNL_AISD-Ex数据集的数量,该数据集包含10,502,917个由碳、氮、氧、氟和硫组成的分子,其中最多有71个非氢原子。Irle小组的博士后研究员PilsunYoo开发了分析所得数据集的工具。
描述分子激发模式的紫外-可见光谱是针对超过1000万个分子中的每一个进行计算的。该信息揭示了靶向分子并分解化合物的某些键所需的光频率。
为每个分子计算的另一个有趣的属性是HOMO-LUMO能隙(最高占据分子轨道和最低未占据分子轨道之间的能隙),它可靠地测量了分子的稳定性。有了这些信息,深度学习模型就可以有效地筛选数据,以识别出具有不同预期用途的有前景的分子。
事实上,LupoPasini和他在ORNL的团队,包括机器学习计算科学家PeiZhang和HPC数据研究科学家JongYoulChoi,正在开发这样一个深度学习模型:HydraGNN。
“HydraGNN架构采用原子结构,将其转换为图形,然后尝试预测输出什么将产生第一原理代码。它是昂贵的第一原理计算的替代模型,”卢波·帕西尼说道。
版权说明:本站所有作品图文均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系我们
相关文章:
- 2023-12-15对古代遗传寄生虫的新认识可能会促进医学突破
- 2023-12-15发现新的霍尔效应它是否违反昂萨格倒数定理
- 2023-12-15超快激光技术可以改善癌症治疗
- 2023-12-15休息的灰礁鲨改变了我们对它们呼吸方式的了解
- 2023-12-15纳米颗粒增强癌症疫苗的潜在功效
- 2023-12-14事实证明鳗草的进化比我们想象的要年轻得多
- 2023-12-14下一代纳米催化剂彻底改变活性电子转移
- 2023-12-14一种制造更符合设计规范的光学器件的新方法
- 2023-12-14研究发现电动汽车可以改善每个人的空气质量但对污染较严重的地区影响较小
- 站长推荐
- 栏目推荐